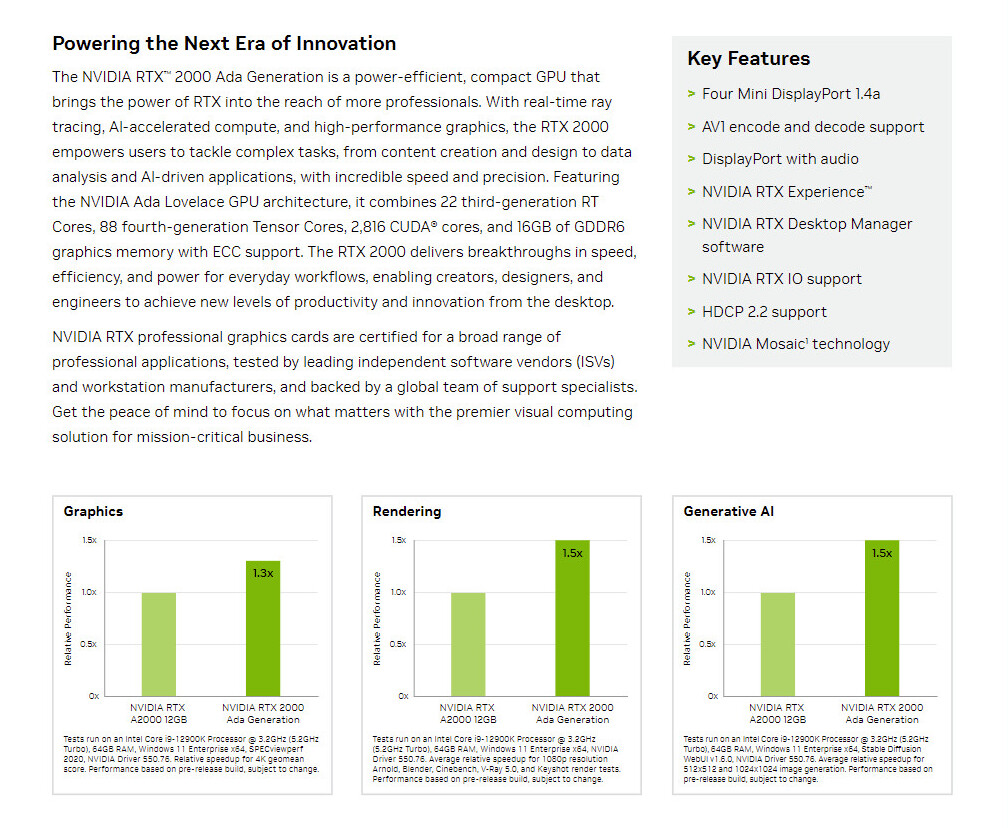
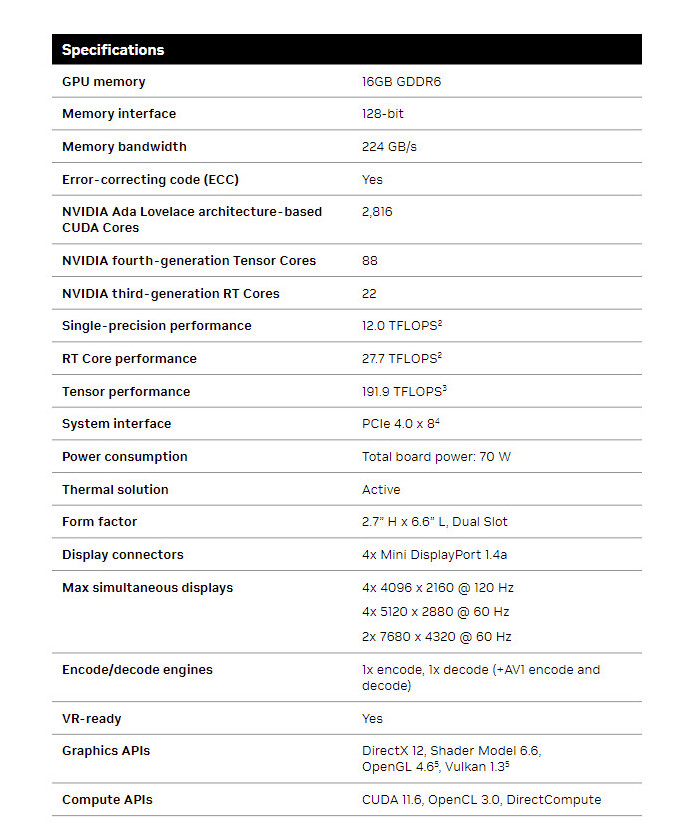
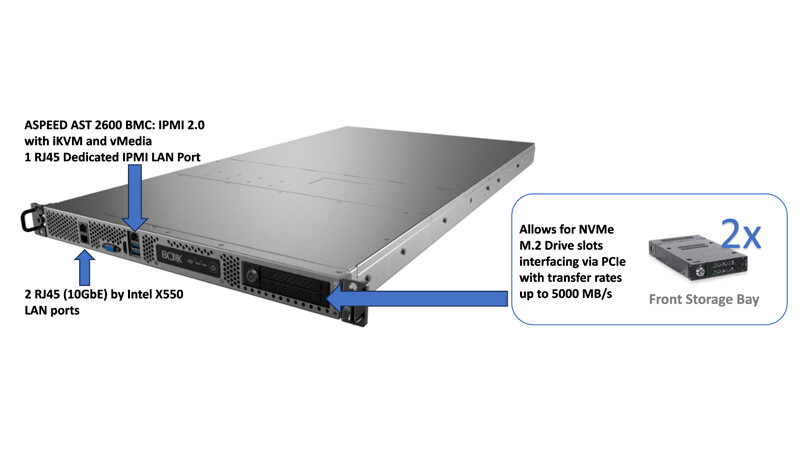
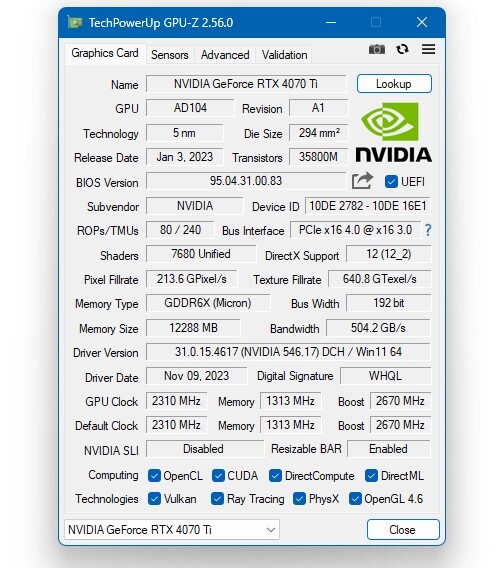
Google's Gemma Optimized to Run on NVIDIA GPUs, Gemma Coming to Chat with RTX
NVIDIA, in collaboration with Google, today launched optimizations across all NVIDIA AI platforms for Gemma—Google's state-of-the-art new lightweight 2 billion- and 7 billion-parameter open language models that can be run anywhere, reducing costs and speeding innovative work for domain-specific use cases.
Teams from the companies worked closely together to accelerate the performance of Gemma—built from the same research and technology used to create the Gemini models—with NVIDIA TensorRT-LLM, an open-source library for optimizing large language model inference, when running on NVIDIA GPUs in the data center, in the cloud and on PCs with NVIDIA RTX GPUs. This allows developers to target the installed base of over 100 million NVIDIA RTX GPUs available in high-performance AI PCs globally.
Teams from the companies worked closely together to accelerate the performance of Gemma—built from the same research and technology used to create the Gemini models—with NVIDIA TensorRT-LLM, an open-source library for optimizing large language model inference, when running on NVIDIA GPUs in the data center, in the cloud and on PCs with NVIDIA RTX GPUs. This allows developers to target the installed base of over 100 million NVIDIA RTX GPUs available in high-performance AI PCs globally.